Planning van een leer/werk-traject machine learning voor bedrijven

 Wanneer je ook met datascience en machine learning wilt starten als gemeentelijke organisatie is het goed om de volgende stappen te doorlopen en de volgende tips ter harte te nemen. De belangrijkste tip is om gewoon te beginnen. Probeer niet alle stappen vooraf te bedenken en dit samen te vatten in een ambtelijk voorstel voor de directie of het college. Er zijn zoveel onzekerheden onderweg, dat een nauwkeurige kosten inschatting moeilijk te maken is. Wel kan onderstaande procesaanpak gebruikt worden, met bijvoorbeeld een doorlooptijd van 6 maanden:
Wanneer je ook met datascience en machine learning wilt starten als gemeentelijke organisatie is het goed om de volgende stappen te doorlopen en de volgende tips ter harte te nemen. De belangrijkste tip is om gewoon te beginnen. Probeer niet alle stappen vooraf te bedenken en dit samen te vatten in een ambtelijk voorstel voor de directie of het college. Er zijn zoveel onzekerheden onderweg, dat een nauwkeurige kosten inschatting moeilijk te maken is. Wel kan onderstaande procesaanpak gebruikt worden, met bijvoorbeeld een doorlooptijd van 6 maanden:
- Voorbereiding: Selecteer een vraagstuk die politiek of ambtelijk van groot belang is. Lees hier mee over bijvoorbeeld het voorspellen van de kosten van de jeugdzorg
- Voorbereiding: Formuleer de vraag die je wilt beantwoorden, en maak het bij aanvang niet te moeilijk. Het doorlopen van een volledig machine learning traject is het eerst van belang. Later kan je de vraag altijd complexer maken. Zorg dus ook dat het niet teveel moeite kost om aan de data te komen. Gebruik samen wel eenzelfde dataset om kennis uit te wisselen.
- Voorbereiding: Zoek één of meerdere maatjes waarmee je op een vast tijdstip samen aan hetzelfde probleem kan werken. Samen werken is een stuk leuker, zeker op de momenten waar je er totaal niet uit komt. En die momenten gaan zeker komen 🙂 Dus zorg dat je de tijd beschikbaar hebt. Doe samen een aantal introductiecursussen Python op Udemy of één van de volgende machine learning cursussen. De cursussen zijn over het algemeen bijzonder vriendelijk geprijsd (< € 100,- per persoon). Maak voor visualisaties bijvoorbeeld ook gebruik van Excel, Microsoft Power BI en van QGis voor GIS-visualisaties. Ook een cursus Power BI kan enorm helpen. Deel eventueel de dataset en je programmacode via Github. Reserveer voldoende tijd: minimaal 1 tot 1,5 dagen per week.
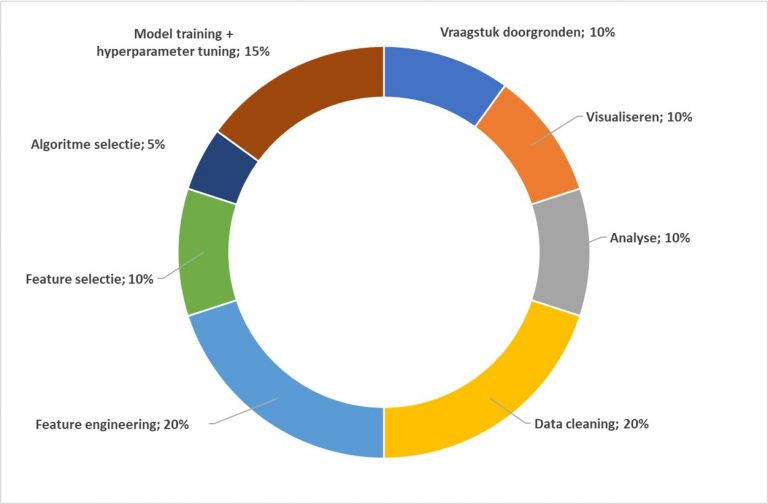
- Voorbereiding: realiseer je dat er veel verschillende kennis nodig is voor het afronden van een machine learning proces. Hieronder een afbeeldingvan de stappen en in meer detail de kennisgebieden:
- Week 1-3: Zorg voor een goede ontwikkelomgeving: zorg allereerst voor voldoende computing power (i7 of i9 CPU met veel cores, min. 16MB intern geheugen, Nvdia-grafische kaart, SSD-opslag)(klik hier voor uitleg over de specs). Installeer je ontwikkelomgeving: Anaconda, Python modules en Jupyter Notebook en eventueel Microsoft Power BI en van QGis. Ga aan de slag met kleine korte python scripts. Probeer direct zinvol commentaar bij je programmacode te zetten. Dat is handig als je het een paar weken later terugleest en om kennis uit te wisselen. Kijk op Udemy cursus python sectie 1, 2 en 3.
- Week 4 – 7: Ga aan de slag met meer python zoals panda’s, numpy, etc. Probeer wel je nieuwe kennis direct toe te passen. Kijk op Udemy python cursus sectie 4, 5 en 6. Hou ook de volgende boeken er bij als naslagwerk:
- Week 4 – 7: Ga op zoek naar de (jeugd)data binnen de organisatie (uit vakapplicaties) en zorg dat deze in CSV of Excel beschikbaar zijn. Als je meerdere datasets gebruikt, zorg dat er overlappende velden zijn. Zorg er ook voor dat gegevens direct gepseudonimiseerd of geanonimiseerd zijn. Treedt in overleg met de Functionaris Gegevensbescherming (FG) om direct goede afspraken te maken over privacy issues. Klik hier voor een overzicht van velddata van Jeugdzorg
- Week 8: Treedt in contact met de specialisten van de vakapplicaties en zorg er voor dat je de betekenis van alle velden goed begrijpt. Vraag stevig door of je de volledige dataset hebt gekregen. Vraag of er vervuiling in zit, of dat velden misbruikt zijn voor een ander doel. Vraag ook of de betekenis van velden misschien is gewijzigd bij jaarovergangen. Klik hier voor meer info over mogelijke vervuiling in Jeugddata. Maar lees ook over uitwisselingstandaarden binnen de jeugdzorg. Probeer ook python te herhalen en echt even te oefenen: kijk op Udemy python cursus sectie 7
- Week 8 – 10: Begin met het inlezen, analyseren en visualiseren van de data. Hou een logboek bij (gewoon een schriftje of Google Keep om te delen). Je zult merken dat je zoveel verschillende dingen probeert dat je op een gegeven moment niet meer alle stappen terug kunt halen als je niet georganiseerd werkt. (Udemy python cursus sectie 8, 9 10)
- Week 8 – 10: Zorg bij de analyse van gegevens, dat je professionele afbeelingen maakt voor bestuurders, directie en vakmedewerkers om ze te enthousiasmeren. Kijk of je misschien het begin van een dashboard kunt ontwikkelen. Deel je resultaten regelmatig!!
- Week 10 – 14: Het is een goed idee om meerdere machine learning modellen te proberen. Sommige modellen zijn gevoelig voor normalisatie en (one-hot) encoding (Neurale netwerken, lineaire regressie-technieken) van de data, andere modellen juist helemaal niet (Random Forest, XGBoost). Door verschillende modellen te proberen, leer je heel veel. kijk op Udemy python cursus sectie 14, 15, 17 en 19 en in het naslagwerk
- Week 10 – 14: Zorg ervoor dat je voldoende weet van Metrics, op basis waarvan je je model kunt fitten en kunt kwalificeren. Weet wat het betekent, en zorg voor goede testdata om nauwkeurigheid van het model te bepalen. Kijk op Udemy python cursus sectie 14
- Week 15 – 16: Modellen worden geoptimaliseerd door hyperparameter tuning. Dit levert zeker een verbetering van de nauwkeurigheid van je model op. Klik hier en hier
- Week 16 – 24: Het maken van Machine learning modellen is veel “trial and error”: herhaal heel veel van de voorgaande stappen. Je zult merken dat de nauwkeurigheid van je model toch te wensen over laat: probeer outliers uit te filteren, of meer of minder data effect heeft, kijk naar meerdere individuele slecht voorspelde records en vraag je af waarom de afwijking zo groot is (monnikenwerk), gebruik random training en test-sets (KFold), probeer hyperparametertuning, treed in overleg met mensen van het sociaal domein om toch nog nieuwe kenmerken te maken, etc. De websites https://machinelearningmastery.com/, https://stackoverflow.com/ en https://towardsdatascience.com/ zijn goede website om oplossingen bij je ML-problemen te vinden
- Week 24 – 30: Als je alle voorgaande stappen hebt gezet, komt er een moment om het datamodel te publiceren en in gebruik te nemen. Nu pas ga je aan de slag met een datawarehouse, waarbij je de ETL-processen inricht. Afhankelijk van het soort model zal er nog meer ingericht moeten worden, en zal de programmacode gepubliceerd moeten worden. Deze cursus op Udemy geeft daar een goede uitleg over.
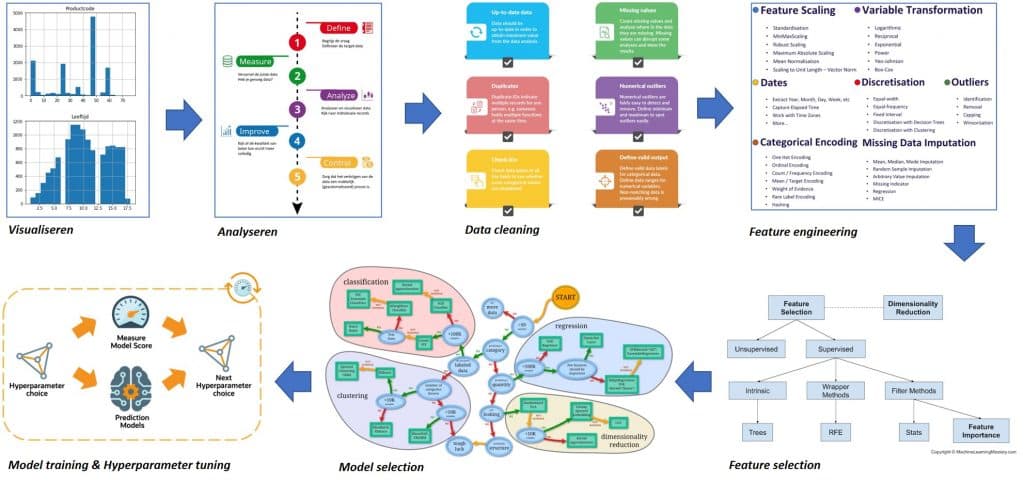
Bovenstaande stappen nemen maanden in beslag, afhankelijk van je vooropleiding. Maar als je alle stappen hebt doorlopen, heb je enorm veel geleerd. Je kan dan ook de organisatie adviseren hoe vakapplicaties slimmer ingericht kunnen worden om er later modellen mee te maken. Of hoe je kunt samenwerken met vakspecialisten om de vraag scherper te definiëren. Alleen op deze manier ga je echt datagedreven werken.